Observability, Black Boxes, and why Signals aren't all that
Over the past six months, I have come to believe that talking about Signals in the context of Observability is a mistake. To properly support distributed systems, we need to change how we observe them - the "Signal Braid" is no longer enough.

Most get introduced to the "Signal Braid" which is based on core monitoring constructs that have been used over the last 30-40 years as a way of easing them into Observability. These are Logs, Traces, and Metrics, and really do make up what Observability practice is today, but they have one massive problem: they focus too much on infrastructure. To combat this, teams should move away from focusing on the golden triangle of Monitoring Signals, and begin with an Observability first mindset. How can they do this? By thinking in Events.
Black Box Thinking
One thing that a lot of people forget about Observability is that it is not an extension of traditional event monitoring or IT Service Management. It is based on a very old engineering practice that focuses on inferring the internal state of a system based on it's external outputs. This attitude should be adopted when you're approaching Observability in your application, ensuring you have a focus on designing ways to make anomalous states reproducible so that they can be fixed. Observability will tell you most of the time that something is rotten in the kitchen, but ultimately, you need to have the right tools to tell you where to look for what is rotten.
What do I mean by this? Well, consider a simple application you've written that monitors your transactions. It polls your bank's transactions and when you move money into your savings account, it checks if you've achieved a "milestone" which is an amount you've set saved in a Datastore somewhere. If you have achieved that milestone, it sends you an email and a text message.
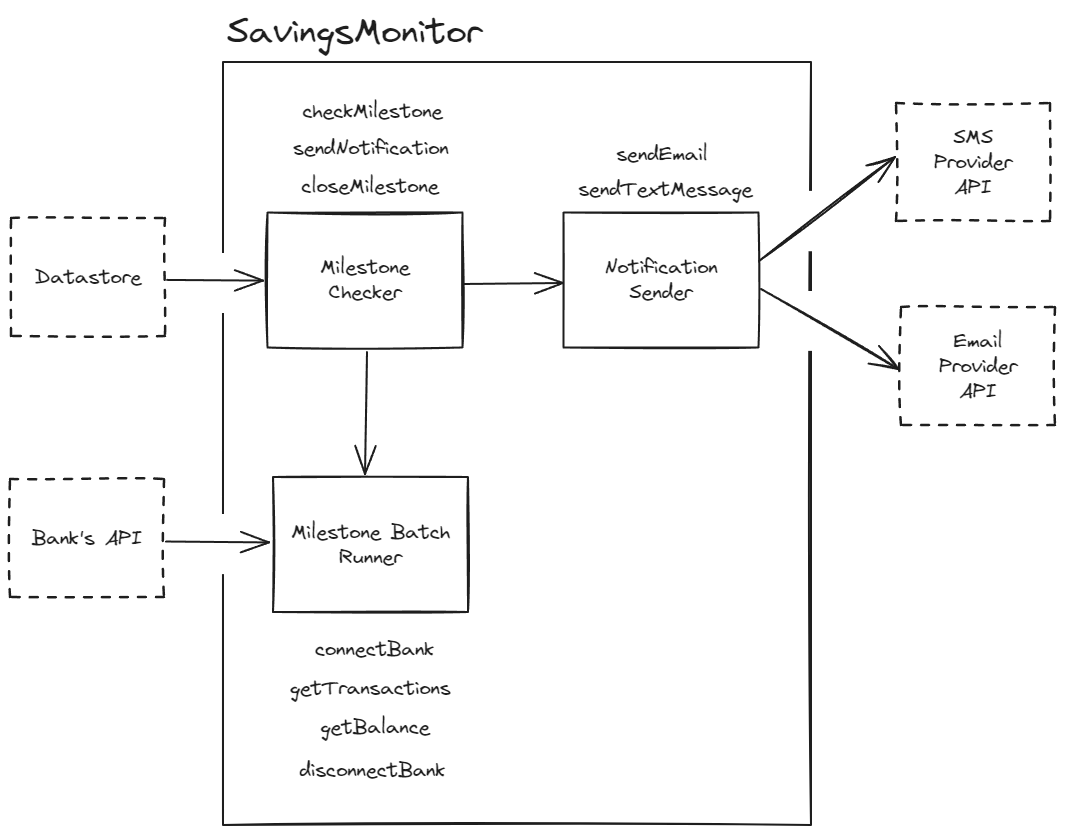
For most engineers, if I told them to implement Observability they're going to reach for gRPC/HTTP monitoring libraries, start monitoring every single HTTP header that could possibly be spat out (even though most of the time, they're using library defaults anyway or the data is in the payload). For good measure, they might even get some Kubernetes metrics, post up a few Istio traces, and start monitoring every piece of infrastructure from the Network Interface up to the Partition Table on an instance's hard disk. They might even have logs that look a little bit like this:

Almost all of this information is absolutely useless, and yet it is what most people will write when they're "implementing Observability". Secrets can be checked in cloud consoles. You told the application to use JSON, so of course it's sending JSON. We know we're starting a HTTP request because our bank has a HTTP API. Even the one bit of data that could be helpful, which is the milestone_balance doesn't have an currency denominator so does it mean $1500 or €1500? Instead this should be made up of multiple events that capture the required information to reproduce the state of the application again if required. There is a bit of a caveat here, and that is with things like status_code, keeping this gives good data for aggregate/analytical queries. But I raise this because, if you had to pick between 1000 auto-instrumented attributes or 10 well thought out manually instrumented attributes, I'd always tell you to go with the latter.
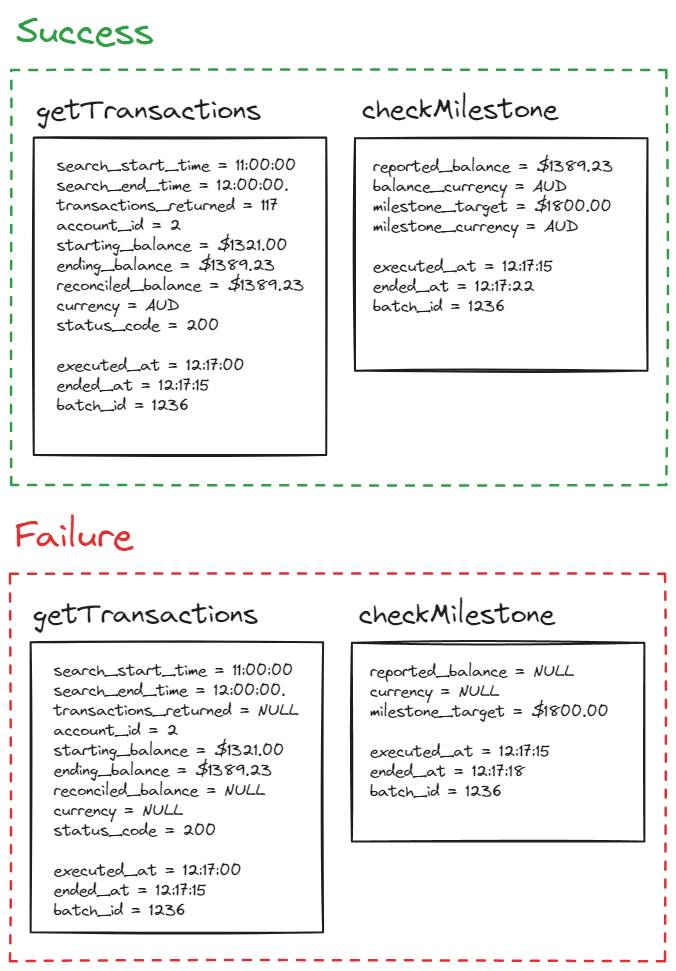
With the above information you could easily get the transaction listing from the bank, process it in the function, and validate the results. It would actually help you solve your application's issues, as opposed to the issues of the underlying infrastructure. Using the example from above, if reconciled_balance is missing, you know something must be amiss: the absence of "black box information" tells you that there is a problem. Even though your request returned 200, your actual function has failed to perform and if you were only focusing on inputs/outputs of HTTP calls, you'd miss this valuable context. You might say "what if we have HTTP errors" or "how will we know the code is actually running", and I would say: emit errors, and adding extra context to include things like line numbers isn't a bad thing, but it definitely shouldn't be your only information. In the same way, a version_number might be great for correlating when an issue happened with a specific release (but it only tells you when an issue occurs, not what is causing the issues). In regards to the infrastructure problem though, I think you should leave that to your SREs. If you're writing code at the right abstraction level, you don't really have access to (or care about) infrastructure details. You are responsible for answering questions about your application. Most of the time if your infrastructure is broken your verbose logs or traces won't matter because there is a good chance your application won't be running.
Focus on delivering information about the things within your control. By enriching your events with as much data as possible, you will be able to understand your system based on the information that is (not) there. You will be able to take that information and replay the scenario to understood what went wrong.
What should we take away from this?
The one thing I want you to take away from this article today, is what you should be aiming to capture when you implement Observability.
An Observability Event should:
- represents a discrete piece of work your application is doing (not the infrastructure it uses to do that work). In other words, "let your abstractions abstract, and focus on your implementation."
- has a defined start and end time.
- can have relationships with other events, but doesn't need to.
- has as many attributes as possible to give you an understanding of the system.
An Observability Event should not:
- prioritise superfluous data that is obvious by other in-context information (e.g. "making a HTTP request" messages or "using this secret").
- primarily focus on underlying infrastructure (unless your application is infrastructure).
- provide characteristics about the data over actual data (e.g. "processed 243 bytes" vs. "processed 117 records from a specified time span").
Sometimes it will be impossible to have Observability that only focuses on your application because maybe your SREs need you to expose something. However, it shouldn't be your first action to grab as much useless information as possible. Carefully crafting each Observability Event you emit will make your life a lot easier when you're troubleshooting your next bug in Production. By removing the noise, you will actually be able to see the issues affecting your systems and use those to solve problems.


